1. Nested Loop Join (NL 조인)
- 특징
- 테이블 간 조인을 한 레코드씩 순차적으로 수행한다.
- 랜덤액세스 방식으로, 대량의 데이터엔 비효율적이다.
- 수행 방법이 For loop와 유사
for tableA (Outer)
for tableB (Inner)
tableA.col == tableB.col
- 성능?
- 선행 테이블의 처리 범위, 스캔 범위가 작아야 유리하다.
선행 테이블은 조건 필터된 데이터를 풀 스캔하기 때문에, 선행 테이블의 데이터 양이 성능에 영향을 끼친다.
해당 결과를 가지고 후행 테이블에 접근할 때 인덱스를 사용하기 때문에, 후행 테이블의 인덱스가 잘 구성되어 있어야 좋은 성능을 낼 수 있다.
=> 선행 테이블의 데이터 양이 적고, 후행 테이블의 인덱스가 잘 구성되어 있을 수록 좋은 성능을 낼 수 있다.
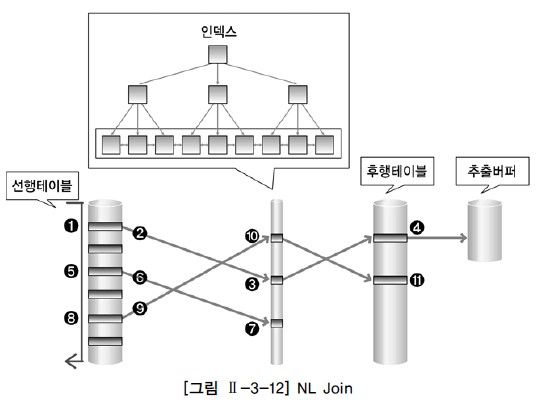
- 선행 테이블에서 조건을 만족하는 첫번째 행을 찾는다.
이 때, 선행 테이블에 주어진 조건을 만족하지 않으면 해당 데이터는 필터링 되어 조인 작업을 진행하지 않는다.
2. 선행 테이블의 조인 키를 가지고 후행 테이블에 조인 키가 존재하는지 찾는다.
-- 조인 키란?
두 개의 테이블을 조인하게 되면 키 값을 기준으로 데이터를 연결하게 된다.
이 때 기준이 되는 키를 조인 키라 한다. 대부분 두 개의 테이블에 공통적으로 들어가 있는 컬럼이 키 값이 된다.
3. 후행 테이블의 인덱스에 선행 테이블의 조인 키가 존재하는지 확인한다.
이 때, 후행 테이블에 존재하지 않으면 선행 테이블 데이터는 필터링되어 조인 작업을 진행하지 않는다.
4. 인덱스에서 추출한 레코드 식별자를 이용하여 테이블을 액세스 한다.
후행 테이블에 주어진 조건까지 모두 만족하면 해당 행을 추출버퍼에 넣는다.
-- 레코드 식별자란?
인덱스에 존재하는, 행의 각 레코드에 대해 고유한 값을 포함하는 데이터 열을 의미한다. 레코드 식별자를 이용하면 데이터의 정확한 위치를 알 수 있다.
2. Sort Merge Join
- 특징
- 조인 칼럼을 기준으로 데이터를 정렬하여 조인을 수행
- 조인 칼럼의 인덱스가 존재하지 않을 경우에도 사용할 수 있는 특징이 있다.
- 랜덤 액세스로 부담이 되는 넓은 범위의 데이터를 처리할 때 이용한다
- 정렬할 데이터가 많아 메모리에 모든 정렬 작업을 수행하기 어려운 경우에는 임시 영역(디스크)를 사용하므로 성능이 떨어질 수 있다.
- Equi Join 뿐만 아니라 Non-Equi Join에 대해서 조인 작업이 가능하다
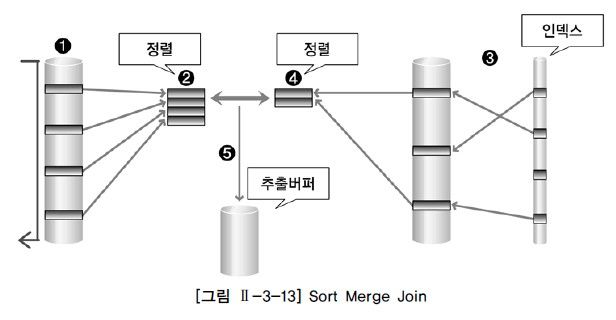
- 선행 테이블에서 주어진 조건을 만족하는 행을 찾는다
- 해당 행들에 대해서, 선행 테이블의 조인 키를 기준으로 정렬 작업을 수행한다.
(선행 테이블에 주어진 조건을 만족하는 모든 행에 대해 1~2 반복)
3. 후행 테이블에서 주어진 조건을 만족하는 행을 찾는다.
4. 해당 행들에 대해서, 후행 테이블의 조인 키를 기준으로 정렬 작업을 수행한다.
(후행 테이블에 주어진 조건을 만족하는 모든 행에 대해 3~4 반복)
5. 정렬된 결과를 이용하여 조인을 수행하며, 조인에 성공하면 추출 버퍼에 넣는다.
3. Hash Join
- 특징
- NL Join의 랜덤 액세스와 Sort Merge Join의 정렬 작업의 부담에 대한 대안으로 등장
- 조인 칼럼의 인덱스가 존재하지 않아도 사용할 수 있는 기법
- 대량의 데이터에 적합
- 동등 조인(Equi Join)에서만 사용할 수 있다.
- Equi Join에서만 사용 가능한 이유 : 해쉬 함수를 적용한 동일한 값은 항상 같은 값으로 해슁됨이 보장되지만, 실제 값은 어떤 값으로 해슁될 지 예측할 수 없다. 하지만 보다 큰 값이 항상 큰 값으로 해슁되고, 작은 값이 항상 작은 값으로 해슁된다는 보장은 없기 때문에 해쉬 조인은 동등 조인(Equi Join)에서만 사용할 수 있다.
- 조인 작업을 수행하기 위해 메모리에 해쉬 테이블을 생성한다. 메모리에 적재할 수 있는 크기보다 커지면 임시 영역 디스크)에 해쉬 테이블을 저장한다.
- 작은 테이블에 접근해 해쉬 함수로 해쉬 테이블을 생성하고,
이후 큰 테이블에 접근해 해쉬 함수를 통해 순차적으로 해쉬 테이블로 접근한다.
- 성능?
- 해쉬 테이블 구성 작업에 부하가 많이 발생하기 때문에, (결과 행의 수가 적은) 작은 테이블을 선행 테이블로 사용하는 것이 좋다.
- 선행 테이블의 결과를 완전히 메모리에 저장할 수 있도록 (임시 영역에 저장하는 작업이 발생하지 않게, CPU 연산을 조금 덜 수행할 수 있게) 결과 행의 수가 적은 테이블을 선행 테이블로 사용하는 것이 좋다.

- 선행 테이블에 대해서 주어진 조건을 만족하는 행을 찾는다.
- 해당 행들에 대해서, 선행 테이블의 조인 키를 기준으로 해쉬 함수를 적용하여 해쉬 테이블을 생성한다.
(선행 테이블에 주어진 조건을 만족하는 모든 행에 대해 1~2 반복)
3. 후행 테이블에서 주어진 조건을 만족하는 행을 찾는다.
4. 해당 행들에 대해서, 후행 테이블에 해쉬 함수를 적용하여 선행 테이블의 해쉬 테이블에서 맞는 버킷(구역?)을 찾는다.
5. 조인에 성공하면 추출 버퍼에 넣는다.
(후행 테이블에 주어진 조건을 만족하는 모든 행에 대해 3~5 반복)
예시 ) https://www.stechstar.com/user/zbxe/study_SQL/45205
SQL학습 및 DB설계 - 그림으로 배우는 ‘오라클 조인의 방식’ 이야기
그림으로 배우는 ‘오라클 조인의 방식’ 이야기 이병국 andongcn@dreamwiz.com 프리랜서 DB 엔지니어로서 동아제약 전산실에서 SW 개발 업무를 시작으로 프리랜서 개발자로 독립해 활동하던 중 우연
www.stechstar.com
'Dev > Oracle' 카테고리의 다른 글
| [Oracle] RMAN 복구 (0) | 2022.06.19 |
|---|---|
| [Oracle] RMAN Backup (0) | 2022.06.17 |
| [Oracle] 대기 이벤트 (0) | 2022.06.15 |
| [Oracle] 계층구조 쿼리 (0) | 2022.06.14 |
| [Oracle] 스칼라 서브쿼리, 인라인뷰, 서브쿼리 (0) | 2022.06.13 |




댓글